本文链接:汉化游戏如何改程序
前言
最近在玩一个叫《冥界狂想曲重制版》的游戏,苦于没有中文,其中又有许多难懂的词汇和句子,游戏体验不好。既然是重制版,那就会有原版,原版还是有汉化的。可要是去玩原版,这重制的意义何在?为了玩上有中文的游戏,何不如自己动手,丰衣足食一把?
汉化流程
不同的游戏肯定是使用不同的机制来呈现文本的,但基本就只有几类,汉化的方式也大体相同。要想汉化,就需要经过以下过程:
- 解包,找到文本和字库
- 修改文本和字库
- 封包
- 修改程序,以使用新字库
我打开这个游戏的根目录,可以看到有名称为grim.en.tab,grim.de.tab……的文件,中间的en,de,……如果对语言很熟悉的话,可以知道这是语言的简称。用文本编辑器(我用的是Notepad++)打开这些文件,果然其中是游戏的文本。每一行前面是ID,后面就是相应的句子,用制表符分隔。
同样,游戏根目录下还有一个叫FontsHD的目录,里面有一些ttf后缀的文件,可以发现这是些字体文件。也就是说,游戏是使用这些字体作字库的。
所以这个游戏并没有解包这一步,汉化所有的内容都放在明面上,这给我省了很多工夫。如果游戏根目录没有这些文件,那它们很可能是被封在了一个包中。可以查看游戏目录下比较大的,看上去是一个包的文件,然后用一些解包工具尝试解包,再从中找出可能的文件。
修改文本和字体
我从旧版汉化游戏中提取到了文本,因为和重制版文本不完全相同,我写了个小工具给两者做了合并。旧版的文本ID和新版的相同,所以如果旧版有就使用旧版文本,否则使用新版文本。这个方法虽然没能汉化所有文本,但也几乎是大部分了。我将原本是英文的文本grim.en.tab里换上了中文,编码使用GBK编码,这一点很重要。
修改字体就更简单一点,从系统的字体目录下选个合适的字体,也需要是ttf格式,我使用的是黑体,将这个字体文件复制多份,替换掉这里所有的字体,注意名称要完全相同。
然后就可以打开游戏看一下了,如果运气好,说不定就直接可以有中文了。

失败了,都是乱码。而且可以注意到,原本应该是“退出”的地方变成了四个方框。按理说即使不能写,两个字应该是两个框,怎么能是四个呢?因为文本使用了GBK编码,中文文字都是占两个字节的,而游戏会按一个字节来读,就变成了四个字,而且会错。这个游戏原本只使用拉丁字母,没有考虑这种情况,才出现了这样的问题。
阅读程序
为了查看和修改程序,需要两个工具,IDA Pro和OllyDbg。前者可以反汇编Windows下的exe程序,并可以分析其中定义的函数,以图的方式呈现出来,便于阅读,也可以手工给函数、内存地址加名字。后者是一个调试器,也可以修改程序。
阅读程序是个大工程,也很需要耐心,我做这个汉化的大部分时间都在阅读程序。人类很难理解一个编译过后的程序,所以这里也需要一些技巧。
首先是从哪里看起。从游戏的主函数看起是不实际的,因为大部分功能和汉化都没关系。在IDA中可以看到exe的字符串表,从中可以找到一些端倪,比如有FontsHD,有grim.en.tab这些和汉化相关的字符串。可以从使用这个字符串的地方看起。比如这里就是一例:使用了/FontsHD/FuturaStd-Heavy.ttf,调用了一个方法,把结果保存了下来。
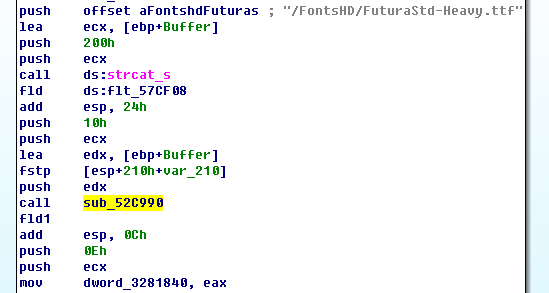
如果用C语言写出来,这段代码大概是这样:
|
1 2 3 4 5 6 7 8 9 |
some_type *dword_3281840; some_other_type *func(...) { byte buffer[0x200]; ... strcat_s(buffer, 0x200, "/FontsHD/FuturaStd-Heavy.ttf"); dword_3281840 = sub_52C990(buffer); ... } |
可以大胆猜测sub_52C990就是读取字体文件的函数,阅读这个函数并参考ttf格式,可以看出确实是这个函数。那么dword_3281840就储存了读取字体的结果。然后只要看哪里使用了dword_3281840,就能找到绘制文本的地方了。在绘制文本的地方可以看出访问了字体的哪些信息,然后再反回来看这些信息是否要修改。
阅读的过程不再详述,只说结论:一共有两处要修改的地方。一是字体读取,原程序只会读取编码为0~254的字符,而这样是读不到汉字的。二是文字绘制,原程序是按一字节一字符的方式绘制,需要改中文字符为两字节一字符。
修改程序
因为是已经编译好的程序,地址信息都已经完全固定,所以不能插入汇编指令了,只能替换指令,且使用的内存大小不能变。可以用变通的方法:将原指令改为跳转,跳到我们的处理语句中,处理结束再跳回去。这个程序的代码段还有大量空余,不需要扩展段就可以写入想要的程序了,还是比较方便的。
字体读取的修改。这个游戏中字体有一个字符表,原本只申请了255*20的空间,这里当然要改为65535*20的空间了。然而,并不能将所有汉字都读入,因为字体在读入时,会将每个字以图像的方式画在一个画布上,这个画布虽然可以扩展(我将它的长宽都扩大到了3倍),但也不能放下所有汉字。我写了个小工具将用到的字排成一个表,存在文件中。当读字体时,先载入这个文件,判断这个字有没有被用到,如果没有用到就不读,这样才节约了画布的空间。相应的代码用C语言写出来如下(实际中还是用汇编写的):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// 此代码只是示意,实际中是汇编代码 char *usedchar = (char*)0; font_info *load_font(char *name) { font_info *info = malloc(sizeof(font_info)); info->char_table = malloc(65535 * 20); // 从255改为65535 memset(info->char_table, 0, 65536 * 20); // 同 ... for (int i=0; i<65535; i++) // 从255改为65535 { /* 以下是新加的代码 */ if (usedchar == 0) { FILE *f = fopen("usedchar.bin", "rb"); // 存了每个字符的使用情况 usedchar = malloc(65536); fread(usedchar, 1, 65536, f); fclose(f); } while (i<65534 && !usedchar[i]) i++; /* 以上是新加的代码 */ ... // 载入编码为i的字符 } ... return info; } |
文字绘制中单字节改双字节的处理。文本使用的是GBK编码,如果某一个字符编码超过0x7F,那么它和之后的字符合起来组成一个汉字。在绘制时也需要输入相应汉字的编码。值得注意的是,字体文件使用的是Unicode编码,在读取字体时需要转换。最简单的方式就是生成一个表,用GBK编码从中查询得到相应的Unicode编码。我对这部分的处理如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
// 此代码只是示意,实际中是汇编代码 unsigned short *gbk_2_unicode = 0; void render_text(char *text, font_info *info, ...) { int text_length; text_length = strlen(text); ... for (int i=0; i<text_length; i++) { int character = text[i]; /* 以下是新加的代码 */ if (character & 0x80 != 0) { if (gbk_2_unicode == 0) { FILE *f = fopen("gbkmap.bin", "rb"); // 存了GBK到Unicode的查找表 gbk_2_unicode = malloc(65536); fread(gbk_2_unicode, 2, 32768, f); fclose(f); } i++; character = (character << 8) + text[i]; // 将两个字节拼接 character = gbk_2_unicode[character - 0x8000]; // 转为Unicode } /* 以上是新加的代码 */ ... // 绘制character } ... } |
大概思路就是这样,除此以外,还有一些细节要考虑。
一,我们的汇编代码相当于是插入了原程序中,汇编中会使用寄存器和栈来储存信息,如果插入的代码使用了寄存器和栈,在使用结束后一定要恢复原值,除非是故意写入新值。另外,如果使用了其他函数,按照规则,eax,ecx和edx都需要手工保存,其他函数可能会改变它们的值。如果用push方式传参数,cdecl的函数(比如fopen,fread,fclose)还需要add esp,4*参数个数,因为它们不会将参数占用的栈清理掉。
二,有些程序运行时会改变基地址,如果使用了绝对寻址的方式而没有改重定向表,就会运行失败。如果想不改重定向表,就只能用相对寻址。如果一定要用绝对寻址,可以用call 下一条指令; pop eax的方式,得到当前指令的地址,以这个地址相对寻址即可。
三,我使用了全局变量usedchar,gbk_2_unicode,有一个问题是存在哪里。我的方法是在数据段中找到一个没人用的空地址填进去,比如两个字符串之间的一些空白。其实存哪里都可以,只要不会被程序其他部分修改和使用就行。
总结
经过以上的工作,汉化终于能运作了,可以打开游戏享受了。

炒饭大神:
您好~我是来自,沈阳的一名普通的女玩家~
“一定是特别的缘分,才可以……”,受家里的影响,从小一路玩游戏长大,FC、MD、SS等等,一直把这个习惯保持到现在,现在工作了,有了一定的闲暇时间,突然想,玩了这么多年游戏,也应该为游戏做一点事情,这也许就是游戏玩家都有的所谓“情怀”吧,所以就开始参与民间的游戏汉化,并且依靠自己还算可以的英语底子帮助做点文本翻译的工作。
目前我们遇到了一个情况,就是我们组正在做一个unity游戏在nintendo switch平台的汉化工作,目前遇到的问题和您文章中提到的问题简直是一摸一样,也是同样无法通过简单替换字库文件实现汉字的显示,需要修改源码,重新指定字库位置,并读取显示,但是我们对汇编语言是完全不懂的,我曾经求助游戏的开放商,愿意无偿提供汉字翻译,但是开发商无情拒绝了,并且没有提供任何理由,只说是“商业原因”。
这反而激起了我们组的斗志,虽然大家都在全力学习相应的知识,但是由于汇编是非常高深的一门学问,因此我们几乎没有进展。通过您的这篇文章,我们茅塞顿开,但是仍然有一些问题不得要领,因此,我冒昧在这里给您留言,不知道能否与您进行即时的沟通,您放心,第一,我们做的汉化工作完全没有商业目的,第二,我们绝不会做伸手党,不会骚扰您,我们只是希望如果有哪些问题不太明白,您能给我们一点方向上的指导,这样我们的学习会更聚焦,更直接。
猜想您工作一定是非常忙碌,对自己的工作与生活也一定有自己的规划和安排,我的QQ号是1016584935 塞壬,如果您能在百忙之中回复,我将万分荣幸,忘了回复也没关系 ^_^
顺祝炒饭大神工作顺利,万事顺心。
如果我印象没错的话,unity游戏有可能不用汇编,而是用C#或者JS写的,有现成的反编译工具,比如C#的ilspy,改起来可能容易些。当然也可能是C++写的,那就免不了看汇编了。
看你的回复感觉你们的汉化组担任程序的同学没能处理这些情况,我的建议是找一些做过unity开发的人或者汉化过unity游戏的汉化组的程序,他们可能有些经验和工具。
先感谢炒饭大神的回复!(我本来以为不会有回复T_T)
目前我们正在研究的并非是PC平台的游戏,而是switch平台的游戏,因此我们只能得到一个只能从IDA读取的.nso格式的文件(相当于是PC平台的.exe文件),经过国外网友的研究,我们可以借助插件成功反编译这个.nso的文件,并且得到汇编的代码。
经过我们的程序人员的研究,游戏是通过unity的sprite font这种自定义字体来显示英文的,读取英文字体的时候直接指定到asset文件中的sprite文件,所以实际上相当于锁定了文字绘制的方法,而我们要做的就是让游戏从别的位置读取字体,因此,只能从汇编着手改变.nso文件中显示文字的方法,和您帖子中所说的方法是一致的,先扩大数组的数量,然后添加代码从别的位置读取汉字(所以说是“特别的”缘分)。
其他的组遇到这个问题的时候就放弃了,但我们确实对这个游戏非常有爱,因此想再尝试一下,也许是因为我们技术差,不知道难点在哪里,所以还在徒劳无功的努力。
目前希望您能帮助的地方有2个:①我们找到了读取文字的代码,如何能够通过修改/增加代码的方式,让程序能够从别的位置读取中文字体并进行绘制;②是个不情之请,还是希望能够和您即时沟通,这个是我的QQ号1016584935。
以上。
再次感谢您能耐着性子读完。